Dissertation von Katharina Holec
In meiner Dissertation an der Heinrich-Heine Universität Düsseldorf untersuche ich die Effekte deskriptiver und substantieller Repräsentation in und durch Beteiligungsverfahren auf die Legimitätseinstellungen von Bürger*innen.
Zusammenfassung
Legitimität – als Summe individueller Überzeugungen über die Angemessenheit und Akzeptanz einer politischen Gemeinschaft, ihres Regimes und ihrer Autoritäten – ist das Schlüsselelement zur Stabilisierung demokratischer Systeme. Unzufriedenheit mit der Demokratie nehmen jedoch zu und in der Bevölkerung entstehen leicht Vorstellungen von Demokratie, die sich voneinander unterscheiden können. Es scheint für ein langfristig stabiles und nachhaltiges politisches System nicht mehr sinnvoll Partizipationsmöglichkeiten auf Wahlen zu beschränken.
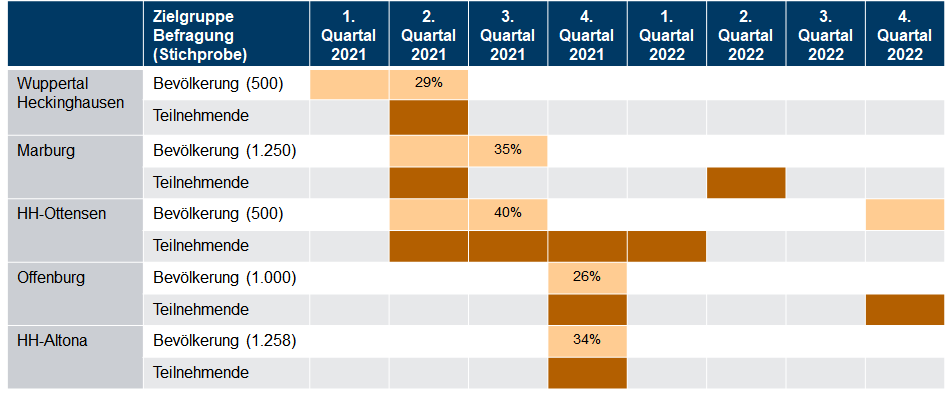
Zur Lösung dieser „Legitimitätsproblem“ schlagen viele Demokratietheoretiker und -forscher mehr Möglichkeiten der politischen Beteiligung am demokratischen Prozess vor. Konsultationen sind ein Mittel, das von den Kommunen häufig eingesetzt wird, um die Zufriedenheit und das Verständnis für politische Prozesse zu erhöhen. Doch die konsultative Beteiligung verspricht oft mehr als sie halten kann. Wie jede politische Beteiligung ist auch die Konsultation verzerrt. Die soziale Ungleichheit in der Gesellschaft beeinflusst, wer sich beteiligt. Und wer teilnimmt, beeinflusst letztlich auch das Ergebnis eines Prozesses. Das Risiko, marginalisierte Stimmen im Prozess zu verlieren, ist in diesen Prozessen hoch.
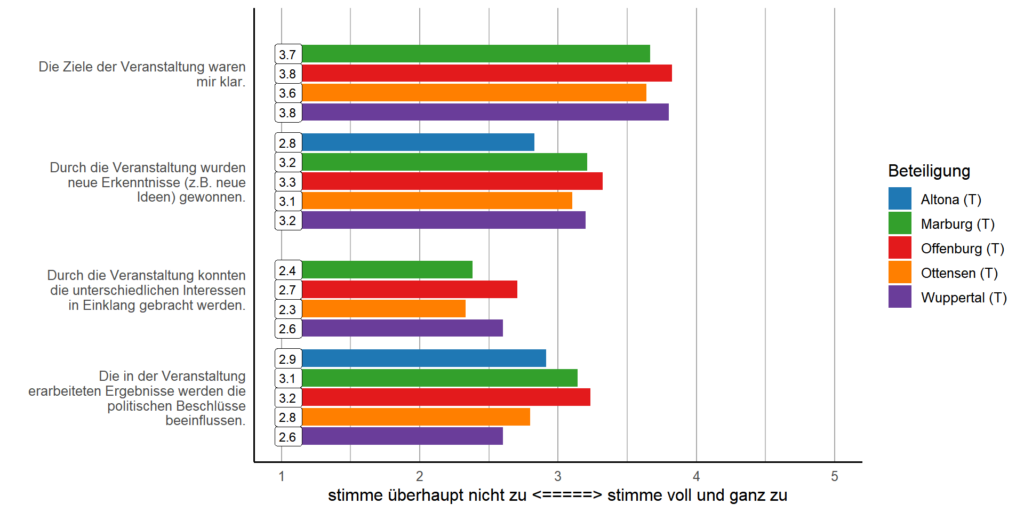
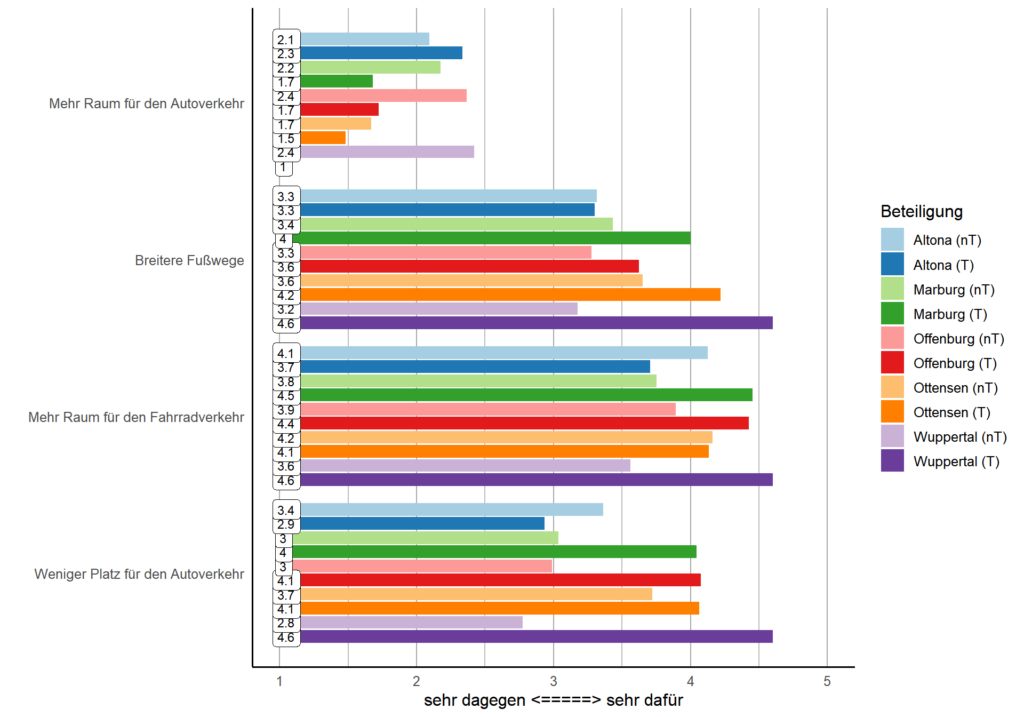
In meine Dissertationsprojekte möchte ich ein detailliertes Verständnis der Vorteile des Einbezugs dieser Stimmen für die Überzeugung von der lokalen demokratischen Legitimität entwickeln. Orientiert an den Ideen von Hannah Pitkin (1972) zur deskriptiven und substantiellen Repräsentation in der Politik entwickle ich ein Modell, dass diese Aspekte im Kontext konsultativer Öffentlichkeitsbeteiligung an der Verkehrswende misst und darstellt.
Ich schaue mir dabei folgende Fragen im Detail an:
(a) Erhöht die deskriptive Repräsentation im Input eines konsultativen Beteiligungsprozesses die substanzielle Repräsentation im Ergebnis eines politischen Prozesses?
(b) Wie wichtig sind deskriptive und substanzielle Repräsentation für die Stärkung der Legitimitätsüberzeugungen nach dem politischen Prozess?
Dabei konzentriere mich speziell auf drei Ebenen des politischen Entscheidungsprozesses: (1) die Input-Ebene, auf der ich die deskriptive Repräsentation für relevant halte, (2) die Throughput-Ebene, auf der ich die substanzielle Repräsentation als „speaking for“ für relevant halte, und (3) die Outcome-Ebene, auf der ich die substanzielle Repräsentation als „acting for“ durch die lokalen Kommunen für relevant halte. Während ich (1) und (2) als relevante Kriterien für die Erhöhung der Legitimitätsüberzeugung durch die Verbesserung des politischen Prozesses betrachte (prozedural), halte ich (3) für die Erhöhung der Legitimitätsüberzeugung durch die Verbesserung der realen Lebensbedingungen für relevant (substanziell).