In dieser Veröffentlichung der Conference on Language Resources and Evaluation stellen Julia Romberg, Laura Mark und Tobias Escher eine Sammlung von annotierten Datensätzen vor, die die Entwicklung von Ansätzen des maschinellen Lernens zur Unterstützung der Auswertung von Beteiligungsbeiträgen fördert.
Zusammenfassung
Behörden in demokratischen Ländern konsultieren regelmäßig die Öffentlichkeit, um den Bürger*innen die Möglichkeit zu geben, ihre Ideen und Bedenken zu bestimmten Themen zu äußern. Bei dem Versuch, die (oft zahlreichen) Beiträge der Öffentlichkeit auszuwerten, um sie in die Entscheidungsfindung einfließen zu lassen, stehen die Behörden aufgrund begrenzter Ressourcen dabei oft vor Herausforderungen.
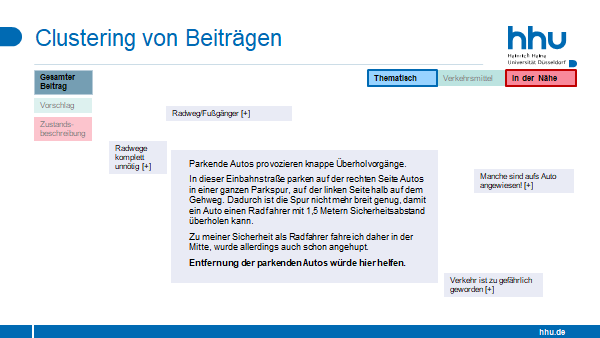
Wir identifizieren mehrere Aufgaben, deren automatisierte Unterstützung bei der Auswertung von Bürger*innenbeteiligung helfen kann. Dies sind i) die Erkennung von Argumenten, genauer gesagt von Prämissen und deren Schlussfolgerungen, ii) die Bewertung der Konkretheit von Argumenten, iii) die Erkennung von textlichen Beschreibungen von Orten, um die Ideen der Bürger*innen räumlich verorten zu können, und iv) die thematische Kategorisierung von Beiträgen. Um in zukünftiger Forschung Techniken entwickeln zu können, die diese vier Aufgaben adressieren, veröffentlichen wir den CIMT PartEval Corpus. Dieser neue und öffentlich verfügbare deutschsprachigen Korpus enthält mehrere tausend Bürgerbeiträge aus sechs mobilitätsbezogenen Planungsprozessen in fünf deutschen Kommunen. Er bietet Annotationen für jede dieser Aufgaben, die in deutscher Sprache für den Bereich der Bürgerbeteiligung bisher entweder überhaupt noch nicht oder nicht in dieser Größe und Vielfalt verfügbar waren.
Ergebnisse
- Der CIMT PartEval Argument Component Corpus umfasst 17.852 Sätze aus deutschen Bürgerbeteiligungsverfahren, die als nicht-argumentativ, Prämisse (premise) oder Schlussfolgerung (major position) annotiert sind.
- Der CIMT PartEval Argument Concreteness Corpus besteht aus 1.127 argumentativen Textabschnitten, die nach drei Konkretheitsstufen annotiert sind: niedrig, mittel und hoch.
- The CIMT PartEval Geographic Location Corpus provides 4,830 location phrases and the GPS coordinates for 2,529 public participation contributions.
- Der CIMT PartEval Thematic Categorization Corpus basiert auf einem neuen hierarchischen Kategorisierungsschema für Mobilität, das Verkehrsarten (nicht-motorisierter Verkehr: Fahrrad, zu Fuß, Roller; motorisierter Verkehr: öffentlicher Nahverkehr, öffentlicher Fernverkehr, kommerzieller Verkehr) und einer Reihe von Spezifikationen wie fließender oder ruhender Verkehr, neue Dienstleistungen sowie Inter- und Multimodalität erfasst. Insgesamt wurden 697 Dokumente nach diesem Schema annotiert.
Publikation
Romberg, Julia; Mark, Laura; Escher, Tobias (2022). A Corpus of German Citizen Contributions in Mobility Planning: Supporting Evaluation Through Multidimensional Classification. In: Proceedings of the Language Resources and Evaluation Conference: 2874–2883, Marseille, France. European Language Resources Association. https://aclanthology.org/2022.lrec-1.308.
Korpus verfügbar unter
https://github.com/juliaromberg/cimt-argument-mining-dataset
https://github.com/juliaromberg/cimt-argument-concreteness-dataset
https://github.com/juliaromberg/cimt-geographic-location-dataset
https://github.com/juliaromberg/cimt-thematic-categorization-dataset