
On October 31, November 7 and December 11, workshops for practitioners were held at which we presented recommendations for action and discussed them with the participants. The participants were administrative staff responsible for citizen participation in the various municipalities with which we cooperated and who were involved in the planning and implementation of the participation processes that we examined in our research.
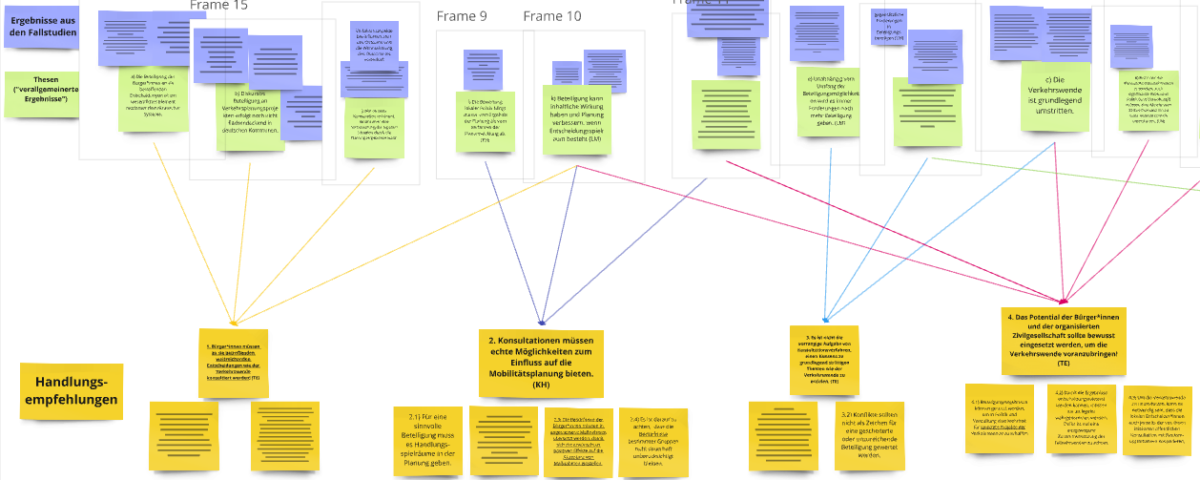
In the course of our investigation of various open consultative participation formats on the topic of urban mobility planning, we were able to generate various findings from which theses can be derived. In a further step, we combined these numerous theses into seven recommendations for action, which are intended to support the implementation of consultative participation formats. At the beginning of the workshops, we used an example to outline the path from insight to recommendations for action before the practitioners themselves got involved and were able to leave comments in our mind map. With the help of digital sticky notes, they added their opinions, additions, criticisms and experiences to the individual recommendations for action. This was followed by discussions on individual recommendations for action. Important points were:
- The usefulness of the recommendations for action in participation practice as tools for classifying one’s own participation
- The usefulness of the recommendations for action in participation practice as an aid to justifying the importance of participation
Overall, the experts agreed that the results of our research are very helpful in communicating the challenges of citizen participation and the resulting consequences to policymakers. In addition, many of the practitioners noted that they found the link to the results of the research clear and structured. Some had the impression that participation and specific consultations are viewed critically in municipal administrations. They share the view that our results can help to train administrative staff and make them aware of the usefulness of participation procedures.
Major points of discussion in the workshops were
- the specificity of the recommendations for action and the inclusion of examples in the presentation of results
- a potentially stronger emphasis on the transparency aspect through the recommendations for action
- an arrangement of the recommendations for action in the chronological order of a participation process
The planners note that the recommendations for action could be made more specific in order to clarify their practical relevance and make them more likely to be applied. In the form in which they were presented, they were rather general and always in strict relation to the results of the research. It was suggested that the recommendations be underpinned with examples from specific participation formats. For example, our research objects could be mentioned, which form the basis of our findings, the theses and thus also the recommendations for action.
Although reformulations and concretizations have been made, examples cannot be found directly in the recommendations. This would have been complicated, especially with regard to the partly abstract quantitative results. However, some examples from the specific participation processes form the basis for the development of the recommendations for action and are sometimes used to underline their importance.
Another aspect that the experts raised is that different tasks and questions arise at different times in a planning process. Some of the seven recommendations for action relate to the planning, implementation or evaluation of the procedures. It was suggested that specific attention should be paid to the participation process and that the recommendations be arranged according to the different stages. This was implemented in the order of the recommendations.
At the end of the workshops, we asked for suggestions for the publication of the results. It was emphasized how important it is for the planners to be able to find these recommendations easily and it was recommended to use existing networks in order to disseminate the results as widely as possible.
We would like to thank the practitioners for their time and important input – and to a large extent for their years of cooperation. We gained many important insights and suggestions that will help us in our work on a helpful and practical publication of recommendations for action.



