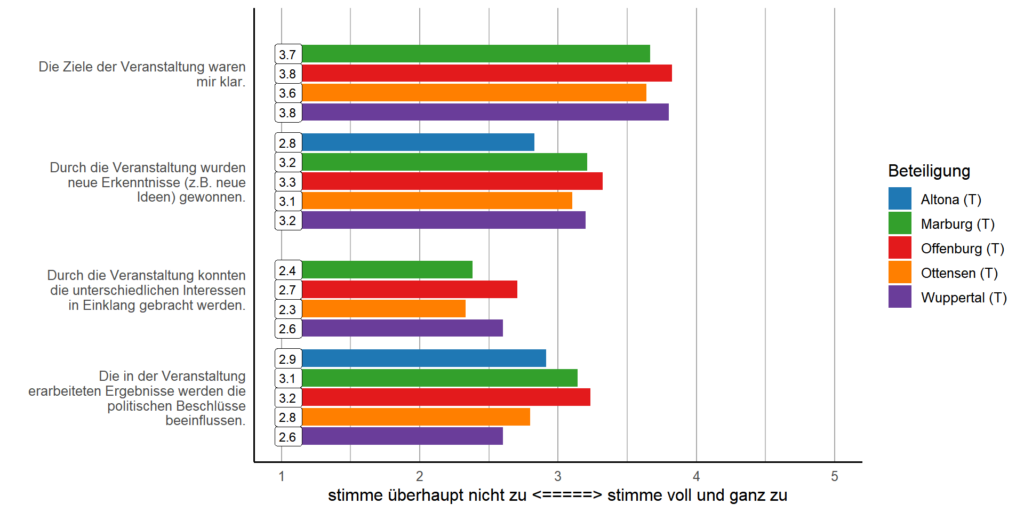
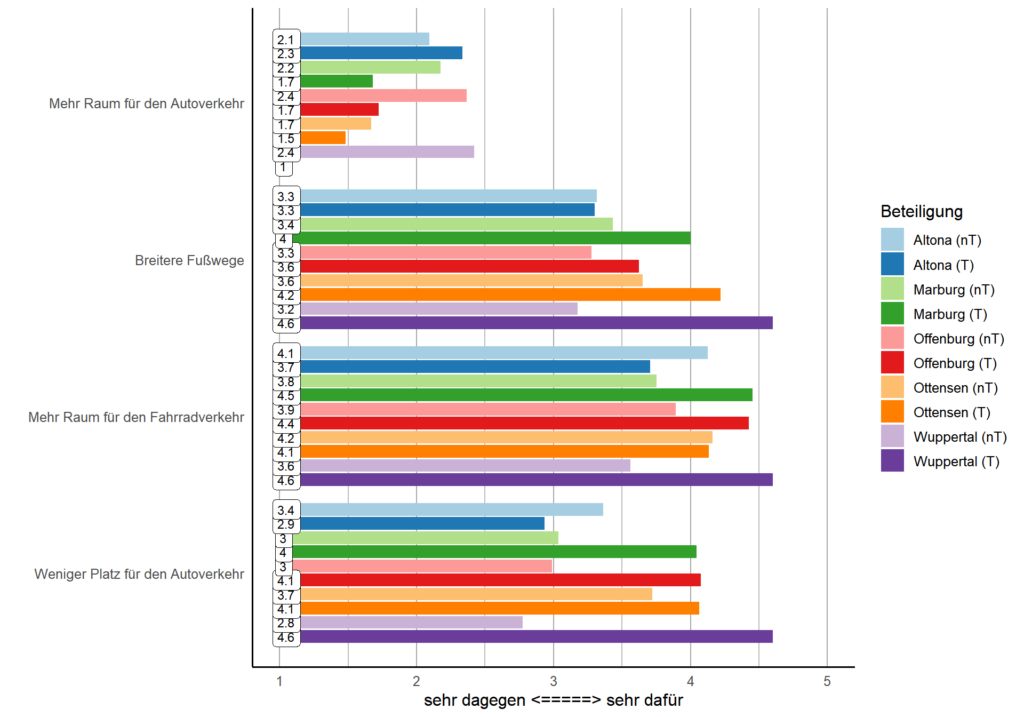
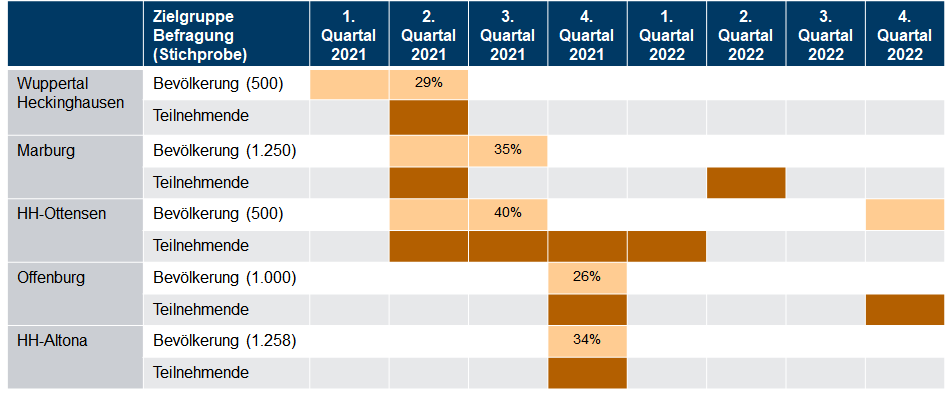
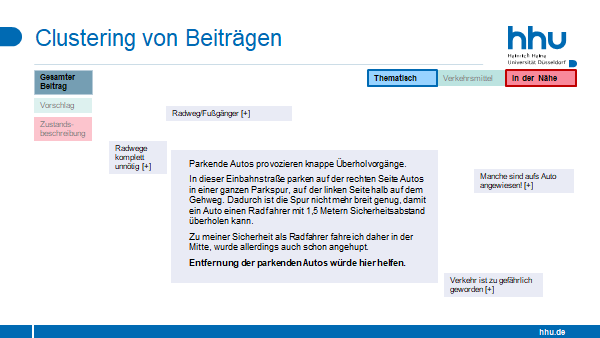
In diesem Artikel in der Zeitschrift Raumforschung und Raumordnung stellen Laura Mark, Katharina Holec und Tobias Escher die Ergebnisse einer Erhebung zu Umfang und Ausgestaltung von Konsultation bei kommunaler Planung mit Mobilitätsbezug vor. Aus diesen Ergebnissen lassen sich Aussagen über die Beteiligungslandschaft in Deutschland ableiten.
Die Ergebnisse wurden im Juni 2023 in einer früheren Fassung auf der 18. Jahrestagung des Arbeitskreises Mobilität und Verkehr (AK MoVe) vorgestellt.
Zusammenfassung
Kommunen als wesentliche Akteure der Verkehrswende nutzen bei der Planung verstärkt konsultative Öffentlichkeitsbeteiligung. Bislang ist jedoch unklar, in welchem Ausmaß sie Beteiligungsverfahren bei der mobilitätsbezogenen Planung einsetzen und wie diese gestaltet werden. Im Hinblick auf die Herausforderungen der Verkehrswende ist eine solche Bestandsaufnahme aber höchst relevant, um die praktische Bedeutung von Partizipationsverfahren abzuschätzen und die Rolle verschiedener Verfahrenstypen und -kontexte besser untersuchen zu können.
Die Erhebung schließt diese Lücke auf Basis einer Auswertung der konsultativen, diskursiven Beteiligungsangebote für mobilitätsbezogene Planungen deutscher Städte seit 2015. Untersucht wurden Städte mit Leitlinien für Bürgerbeteiligung, die mit einer Zufallsauswahl aus ‘typischen‘ Kommunen in Nordrhein-Westfalen, Baden-Württemberg und Sachsen sowie den drei deutschen Stadtstaaten verglichen wurden.
Auf Basis dieser rund 180 Städte und 350 Verfahren wird deutlich, dass diskursive Konsultationen zwar regelmäßig durchgeführt werden, vor allem in Kommunen mit Leitlinien sowie größeren Städten. Kritisch zu bewerten ist, dass die dabei eingesetzten Formate meist nur bestimmte Gruppen der Bevölkerung erreichen können und dass sich oft keine Angaben zu den Ergebnissen der Beteiligung auffinden lassen. Damit kommen die Potentiale diskursiver Bürger*innenbeteiligung bei der Bewältigung der kommunalen Verkehrswende bislang zu wenig zum Tragen.
Wesentliche Ergebnisse
- Beteiligung an kommunalen Planungsverfahren mit Mobilitätsbezug ist keine Ausnahme mehr, aber auch noch nicht die Regel. Basierend auf den Daten unserer Stichprobe kann man davon ausgehen, dass es in den meisten Kommunen in Deutschland im betrachteten Zeitraum keine Möglichkeit gab, sich an solchen Verfahren zu beteiligen.
- Generell beteiligten Städte mit Leitlinien ihre Bürger*innen häufiger, öfter und mit vielfältigeren Themen und Formaten. Mittel- und Großstädte beteiligten deutlich häufiger als Kleinstädte.
- Bei den eingesetzten Beteiligungsformaten zeigen sich Schwächen: Der Großteil der Kommunen setzten auf selbst-selektierte Auswahlprozesse. Erste Versuche mit zielgruppenspezifischen Formaten oder vereinzelt auch Zufallsauswahl sind v.a. in den Kommunen mit Leitlinien und in den Stadtstaaten zu finden. Auch wurde ein großer Anteil der Verfahren rein online durchgeführt.
- Für 5 bis 10% der Verfahren ließ sich kein aktueller Stand auffinden, für einen größeren Teil war unklar, was nach der Konsultation passierte. Dies trifft für alle Kommunen zu, wenn auch weniger stark auf solche mit Leitlinien und lässt sich als Mangel an Transparenz und Wirkung der Beteiligung werten.
Publikation
Mark, Laura; Holec, Katharina; Escher, Tobias (2024). Die Beteiligung von Bürgerinnen und Bürgern bei kommunalen Mobilitätsprojekten. Eine quantitative Erhebung konsultativer Beteiligungsverfahren in Deutschland. In: Raumforschung und Raumordnung: 1-16. DOI: 10.14512/rur.2239.
Datengrundlage
Die Datengrundlage, also die systematisch erhobene Zusammenstellung der Beteiligungsverfahren und deren Kodierung nach bestimmten Aspekten, findet sich zur Recherche und zum Download hier.