

[mehr in Kürze]
Kategorie: Auswertung
5. Praxisworkshop zu aus den Ergebnissen generierten Handlungsempfehlungen
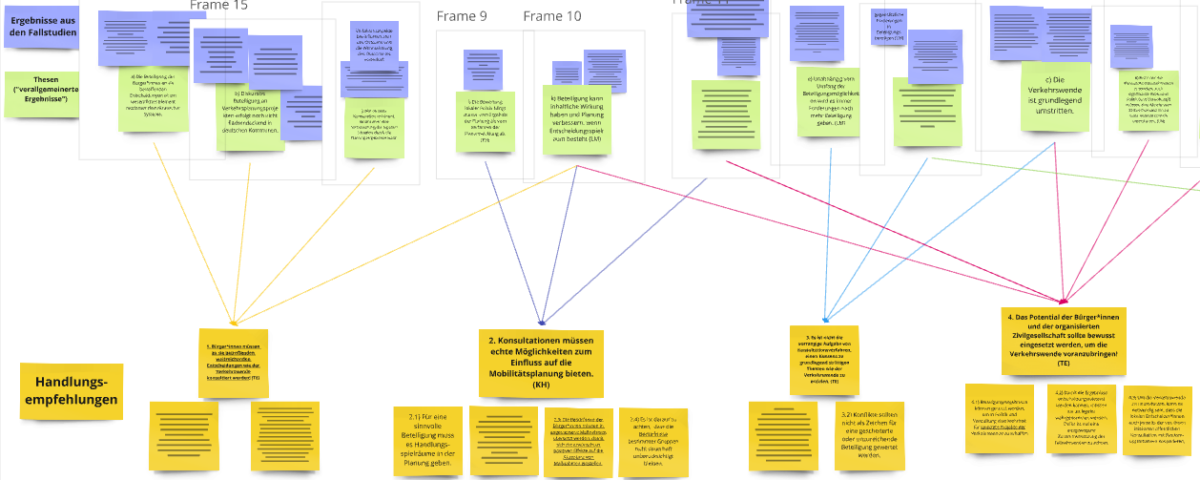
Am 31. Oktober, 07. November und 11. Dezember haben Praxisworkshops stattgefunden, bei denen wir Handlungsempfehlungen vorgestellt und mit den Teilnehmenden diskutiert haben. Teilgenommen haben Verwaltungsmitarbeiter*innen, die in den verschiedenen Kommunen mit denen wir kooperiert haben, für Bürger*innenbeteiligung verantwortlich sind und die an der Planung und Durchführung der Beteiligungsverfahren beteiligt waren, die wir in unserer Forschung untersucht haben.
Im Zuge unserer Untersuchung verschiedener offener konsultativer Beteiligungsformate zum Thema urbaner Mobilitätsplanung, konnten wir verschiedene Erkenntnisse generieren, aus denen sich Thesen ableiten lassen. Diese Vielzahl an Thesen haben wir in einem weiteren Schritt zu sieben Handlungsempfehlungen verbunden, die bei der Umsetzung konsultativer Beteiligungsformate unterstützen sollen. Zu Beginn der Workshops haben wir den Weg von der Erkenntnis zur Handlungsempfehlung an einem Beispiel skizziert, bevor die Praktiker*innen selbst tätig wurden und in unserer Mindmap Kommentare hinterlassen konnten. Mit Hilfe digitaler Klebezettel haben sie ihre Meinungen, Ergänzungen, Kritikpunkte und Erfahrungen zu den einzelnen Handlungsempfehlungen angebracht. Im Anschluss daran gab es dann Diskussionen zu einzelnen Handlungsempfehlungen. Wichtige Punkte waren:
- Die Nützlichkeit der Handlungsempfehlungen in der Beteiligungspraxis als Tools zur Einordnung der eigenen Beteiligung
- Die Nützlichkeit der Handlungsempfehlungen in der Beteiligungspraxis als Begründungshilfe für die Wichtigkeit von Beteiligung
Die Expert*innen waren sich insgesamt einig, dass die Ergebnisse unserer Forschung sehr hilfreich sind, um gegenüber der Politik die Herausforderungen der Bürger*innenbeteiligung und die daraus folgenden Konsequenzen zu kommunizieren. Zusätzlich merkten viele der Praktiker*innen an, dass sie die Verknüpfung zu den Ergebnissen der Forschung übersichtlich und strukturiert fanden. Einige hatten den Eindruck, dass Beteiligungen, spezifischer Konsultationen in kommunalen Verwaltungen kritisch gesehen werden. Sie teilen die Einschätzung, dass unsere Ergebnisse einen Beitrag leisten können Verwaltungsmitarbeiter*innen zu schulen und ihnen die Nützlichkeit von Beteiligungsverfahren nahe zu bringen.
Größere Diskussionspunkte in den Workshops waren:
- die Konkretheit der Handlungsempfehlungen und das Einbinden von Beispielen in die Ergebnisdarstellung
- eine potentiell stärkere Betonung des Transparenzaspekts durch die Handlungsempfehlungen
- eine Anordnung der Handlungsempfehlungen in der zeitlichen Reihenfolge eine Partizipationsprozesses
Die Planer*innen merken an, dass die Handlungsempfehlungen konkretisiert werden könnten, um den Praxisbezug zu verdeutlichen und sie eher Anwendung finden zu lassen. In ihrer vorgestellten Form waren sie eher allgemein Gehalten und immer in strenger Relation zu den Ergebnissen der Forschung. Es wurde vorgeschlagen die Empfehlungen mit Beispielen aus konkreten Beteiligungsformaten zu unterfüttern. Beispielsweise könnten dafür unsere Forschungsgegenstände genannt werden, die unseren Erkenntnissen, den Thesen und damit auch den Handlungsempfehlungen zu Grunde liegen.
Obwohl Umformulierungen und Konkretisierungen vorgenommen wurden, sind Beispiele nicht direkt in den Empfehlungen zu finden. Dies wäre vor allem in Bezug auf die teils abstrakten und quantitativen Ergebnisse kompliziert gewesen. In Teilen bilden Beispiele aus den konkreten Partizipationsverfahren aber die Grundlage für das Erarbeiten der Handlungsempfehlungen und werden zum Teil zum Unterstreichen der Wichtigkeit genutzt.
Ein weiterer Aspekt, den die Expert*innen angebracht haben ist, dass sich in einem Planungsprozess zu verschiedenen Zeitpunkten unterschiedliche Aufgaben und Fragen stellen. Die sieben Handlungsempfehlungen beziehen sich teilweise auf die Planung, Umsetzung oder Auswertung der Verfahren. Dabei wurde vorgeschlagen spezifisch auf den Partizipationsprozess zu achten und die Handlungsempfehlungen entsprechend anzuordnen. Dies wurde umgesetzt.
Zum Abschluss der Workshops haben wir nach Anregungen für die Veröffentlichung der Ergebnisse gefragt. Dabei wurde betont wie wichtig eine gute Auffindbarkeit für die Planer*innen ist und empfohlen bereits bestehende Netzwerke zu nutzen, um die Ergebnisse möglichst weit streuen zu können.
Wir bedanken uns bei den Praktiker*innen für Ihre Zeit und den wichtigen Input – sowie in großen Teilen die jahrelange Kooperation. Es kamen viele wichtige Erkenntnisse und Anregungen zusammen, die uns bei der Arbeit an einer hilfreichen und praxisnahen Veröffentlichung der Handlungsempfehlungen helfen.
KI zur Auswertung von Beteiligung? Das Potenzial von Sprachmodellen zur Erkennnung von Verkehrsmitteln in Beteiligungsbeiträgen
In diesem Artikel in der Zeitschrift Internationales Verkehrswesen stellen Laura Mark, Julia Romberg und Tobias Escher ein Sprachmodell vor, mit dessen Hilfe Verkehrsmittel in Beteiligungsbeiträgen zuverlässig erkannt werden. Sie zeigen damit, dass überwachtes maschinelles Lernen die Auswertung von Beteiligungsbeiträgen mobilitätsbezogener Online-Beteiligungsverfahren sinnvoll unterstützen kann.
Zusammenfassung
Konsultationen sind ein wichtiger Bestandteil der Verkehrsplanung und können dazu beitragen, Wissen aus der Bevölkerung in den Planungsprozess zu integrieren. Insbesondere durch Onlineformate kommen allerdings oft große Mengen an Beiträgen zustande, deren gründliche Auswertung ressourcenintensiv ist. Mit dem Einsatz von KI wird die Hoffnung verbunden, diese zu unterstützen.
Das in diesem Artikel vorgestellte Sprachmodell beruht auf dem Konzept des überwachten maschinellen Lernens zur Textklassifikation. Dabei werden vortrainierte Modelle mithilfe kleinerer Datensätze nachtrainiert. So kann ein Modell an einen speziellen Anwendungsbereich, wie beispielsweise verkehrsplanerische Konsultationsprozesse, angepasst werden.
Hier wurde eine vortrainierte deutschsprachige Version des leistungsfähigen RoBERTa Sprachmodells als Ausgangspunkt genommen. Anhand eines Kategorisierungsschemas, das hauptsächlich nach erwähnten Verkehrsmitteln unterscheidet, wurden 1.700 Beiträge aus sieben verkehrsplanerischen Konsultationsprozessen manuell kodiert. Die so entstandenen Daten wurden zum Teil als Trainingsdaten zum Fine-Tuning des Sprachmodells und zum Teil zur Evaluation genutzt.
Ergebnisse
- Insgesamt konnte gezeigt werden, dass sich bereits heute verfügbare Sprachmodelle eignen, um die Auswertung von Konsultationsprozessen in der Praxis zu unterstützen. Das hier entwickelte Sprachmodell zur Erkennung der Verkehrsmittel kann dabei als Basis für eine konkrete Anwendung dienen.
- Das nachtrainierte RoBERTa-Sprachmodell ist sehr gut in der Lage, die passenden Verkehrsmittel zuzuordnen. Das von uns vorgestellte Modell kann zuverlässig immer deutlich über 90% der Beiträge korrekt den darin genannten Verkehrsmitteln zuordnen.
- Für die Verfahren, auf deren Beiträgen das Modell trainiert worden war, konnten im Durchschnitt 97% der Kategorien korrekt zugeordnet werden (auf einem separaten Testset). Für Beiträge aus anderen verkehrsbezogenen Beteiligungsverfahren konnten mit einer Genauigkeit von 91 bis 94% weiterhin sehr zuverlässig die passenden Verkehrsmittel zugeordnet werden.
- Die Leistung des Modells verschlechtert sich also kaum, wenn es auf bislang unbekannte Daten aus mobilitätsbezogenen Beteiligungsverfahren angewandt wird. Das bedeutet, dass eine manuelle Kodierung im Vorfeld zumindest bei ähnlich aufgestellten Beteiligungsverfahren entfallen kann, was den Aufwand deutlich reduziert.
Publikation
Mark, Laura; Romberg, Julia; Escher, Tobias (2024). KI zur Auswertung von Beteiligung? Das Potenzial von Sprachmodellen zur Erkennung von Verkehrsmitteln in Beteiligungsbeiträgen. In: Internationales Verkehrswesen 76 (1): 12-16. DOI: 10.24053/iv-2024-0003
Kodierung und Bereitstellung von Datensätzen
Im Rahmen unseres Projekts haben wir an der manuellen Annotation einer Vielzahl von Datensätzen gearbeitet mit dem Ziel die Entwicklung von KI-Verfahren zu Auswertung von Beteiligungsbeiträgen zu unterstützen.
Überwachte maschinelle Lernverfahren (supervised machine learning) benötigen Trainingsdatensätze um Eigenschaften und Muster der jeweiligen Kodierungen erlernen zu können. Im Bereich von Bürger*innenbeteiligung fehlt es hier an umfassend kodierten deutschsprachigen Datensätzen. Um den Bedarf zu decken, haben wir deshalb an der Kodierung deutschsprachiger Beteiligungsverfahren aus dem Bereich Mobilität nach vier Dimensionen gearbeitet:
- Erstens haben wir Verfahren thematisch nach Verkehrsmitteln, weiteren Ansprüchen an den Raum, sowie unmittelbar zu behebenden Mängeln kodiert.
- Zweitens haben wir Verfahren nach argumentativen Sätzen kodiert und diese in Vorschläge und Zustandsbeschreibungen unterteilt.
- Drittens haben wir argumentativen Sinneinheiten zugeordnet, wie konkret diese sind.
- Viertens haben wir textuelle Ortsangaben kodiert.
Eine detailliertere Beschreibung der Datensätze – Stand Juni 2022 – findet sich in unserer Publikation: Romberg, Julia; Mark, Laura; Escher, Tobias (2022, June). A Corpus of German Citizen Contributions in Mobility Planning: Supporting Evaluation Through Multidimensional Classification. Seitdem haben wir weiter an der thematischen Kodierung der Datensätze gearbeitet und unser Schema der Verkehrsmittel überarbeitet.
Die folgende Tabelle zeigt den aktuellen Stand der Kodierung und wird fortlaufend aktualisiert: Google-Sheet
Im Einklang mit unserer Open Source-Richtlinie werden die kodierten Datensätzen der Öffentlichkeit nach Möglichkeit unter Creative Commons CC BY-SA License verfügbar gemacht.
Basierend auf diesen Datensätzen sind eine Reihe von Publikationen entstanden. Diese finden Sie unter https://www.cimt-hhu.de/gruppe/romberg/romberg-veroeffentlichungen/.
Masterarbeit zur thematischen Klassifikation von Beteiligungsbeiträgen mit Active Learning
Im Rahmen seiner Masterarbeit im MA Informatik an der Heinrich-Heine-Universität Düsseldorf hat sich Boris Thome mit der Klassifikation von Beteiligungsbeiträgen nach den enthaltenen Themen beschäftigt. Diese Arbeit führt die Arbeit von Julia Romberg und Tobias Escher fort, indem eine feinere Einteilung der Beiträge nach Unterkategorien untersucht wurde.
Zusammenfassung
Politische Behörden in demokratischen Ländern konsultieren die Öffentlichkeit regelmäßig zu bestimmten Themen, doch die anschließende Auswertung der Beiträge erfordert erhebliche personelle Ressourcen, was häufig zu Ineffizienzen und Verzögerungen im Entscheidungsprozess führt. Eine der vorgeschlagenen Lösungen ist die Unterstützung der menschlichen Analyst*innen bei der thematische Gruppierung der Beiträge durch KI.
Überwachtes maschinelles Lernen (supervised machine learning) bietet sich für diese Aufgabe an, indem die Vorschläge der Bürger nach bestimmten vordefinierten Themen klassifiziert werden. Durch die individuelle Natur vieler öffentlicher Beteiligungsverfahren ist der manuelle Aufwand zur Erstellung der benötigten Trainingsdaten jedoch oft zu teuer. Eine mögliche Lösung, um die Menge der Trainingsdaten zu minimieren, ist der Einsatz von Active Learning. In unser vorherigen Arbeit konnten wir zeigen, dass Active Learning den manuellen Annotationsaufwand zur Kodierung von Oberkategorien erheblich reduzieren kann. In dieser Arbeit wurde nachfolgend untersucht, ob dieser Vorteil auch dann noch gegeben ist, wenn die Oberkategorien in weitere Unterkategorien unterteilt werden. Eine besondere Herausforderung besteht darin, dass einige der Unterkategorien sehr selten sein können und somit nur wenige Beiträge umfassen.
In der Evaluation verschiedener Methoden wurden Daten aus Online-Beteiligungsprozessen in drei deutschen Städten verwendet. Die Ergebnisse zeigen, dass die maschinelle Klassifikation von Unterkategorien deutlich schwerer ist als die Klassifikation der Oberkategorien. Dies liegt an der hohen Anzahl von möglichen Unterkategorien (30 im betrachteten Datensatz), die zusätzlich sehr ungleich verteilt sind. Im Fazit ist weitere Forschung erforderlich, um eine praxisgerechte Lösung für die flexible Zuordnung von Unterkategorien durch maschinelles Lernen zu finden.
Publikation
Thome, Boris (2022): Thematische Klassifikation von Partizipationsverfahren mit Active Learning. Masterarbeit am Institut für Informatik, Lehrstuhl für Datenbanken und Informationssysteme, der Heinrich-Heine-Universität Düsseldorf. (Download)
Masterarbeit zur automatisierten Klassifikation von Argumenten in Beteiligungsbeiträgen
Im Rahmen ihrer Masterarbeit im MA Informatik an der Heinrich-Heine-Universität Düsseldorf hat sich Suzan Padjman mit der Klassifikation von Argumentationskomponenten in Beteiligungsbeiträgen beschäftigt. Diese Arbeit führt die bisherige Arbeit unseres Teams fort, indem Fälle betrachtet werden, in denen argumentative Sätze sowohl einen Vorschlag als auch eine Zustandsbeschreibung enthalten können.
Zusammenfassung
Öffentlichkeitsbeteiligungsverfahren ermöglichen es den Bürger*innen, sich an kommunalen Entscheidungsprozessen zu beteiligen, indem sie ihre Meinung zu bestimmten Themen äußern. Kommunen haben jedoch oft nur begrenzte Ressourcen, um eine möglicherweise große Menge an Textbeiträgen zu analysieren, welche zeitnah und detailliert ausgewertet werden müssen. Eine automatisierte Unterstützung bei der Auswertung kann daher hilfreich sein, z.B. um Argumente zu analysieren.
Bei der Klassifikation von argumentativen Sätzen nach Typen (hier: Vorschlag oder Zustandsbeschreibung) kann es vorkommen, dass ein Satz mehrere Komponenten eines Arguments beinhaltet. In diesem Fall besteht die Notwendigkeit einer Multi-Label Klassifikation, bei der mehr als eine Kategorie zugeordnet werden kann.
Um dieses Problem zu lösen, wurden in der Arbeit verschiedene Methoden zur Multi-Label Klassifikation von Argumentationskomponenten verglichen (SVM, XGBoost, BERT und DistilBERT). Im Ergebnis zeigte sich, dass BERT-Modelle eine macro F1-Vorhersagegüte von bis zu 0,92 erreichen können. Dabei weisen die Modelle datensatzübergreifend eine robuste Performance auf – ein wichtiger Hinweis auf den praktischen Nutzen solcher Verfahren.
Publikation
Padjman, Suzan (2022): Mining Argument Components in Public Participation Processes. Masterarbeit am Institut für Informatik, Lehrstuhl für Datenbanken und Informationssysteme, der Heinrich-Heine-Universität Düsseldorf. (Download)
Projektarbeit zur automatisierten Erkennung von Verortungen in Beteiligungsbeiträgen
Im Rahmen ihrer Projektarbeit im MA Informatik an der Heinrich-Heine-Universität Düsseldorf hat sich Suzan Padjman mit der Entwicklung von Verfahren zur automatisierten Erkennung von textuell beschriebenen Ortsangaben in Beteiligungsverfahren beschäftigt.
Zusammenfassung
Im Kontext der Verkehrswende sind konsultative Verfahren ein beliebtes Hilfsmittel, um Bürger*innen die Möglichkeit zu geben, ihre Interessen und Anliegen zu vertreten und einzubringen. Insbesondere bei mobilitätsbezogenen Fragen ist ein wichtiger Analyseaspekt der gesammelten Beiträge, welche Orte (z.B. Straßen, Kreuzungen, Rad- oder Fußwege) Probleme aufweisen und verbesserungswürdig sind, um die Mobilität nachhaltig zu fördern. Eine automatisierte Identifikation von solchen Verortungen hat das Potential, die ressourcenintensive manuelle Auswertung zu unterstützen.
Ziel dieser Arbeit war es daher, mithilfe von Methoden aus dem Natural-Language-Processing (NLP) eine automatisierte Lösung zur Identifikation von Verortungen zu finden. Dazu wurde eine Verortung als die Beschreibung eines konkreten Ortes eines Vorschlags definiert, welche auf einer Karte markiert werden könnte. Beispiele für Verortungen sind Straßennamen, Stadtteile und eindeutig zuordenbare Plätze, wie z.B. “in der Innenstadt” oder “am Ausgang des Hauptbahnhofs”. Reine Lagebeschreibungen ohne eine konkrete Ortszugehörigkeit wurden dagegen nicht als Verortung betrachtet. Methodisch wurde die Aufgabe als eine Sequence-Labeling-Aufgabe betrachtet, da Verortungen häufig aus mehreren hintereinanderfolgenden Token, sogenannten Wortsequenzen, bestehen.
Im Vergleich verschiedener Modelle (spaCy NER, GermanBERT, GBERT, dbmdz BERT, GELECTRA, multilingual BERT, multilingual XLM-RoBERTa) auf zwei deutschsprachigen Beteiligungsdatensätzen zur Radinfrastruktur in Bonn und Köln Ehrenfeld zeigte sich, dass GermanBERT die besten Ergebnisse erzielt. Dieses Modell kann Token, die Teil einer textuellen Ortsbeschreibung sind, mit einem vielversprechenden macro F1-Score von 0,945 erkennen. In zukünftiger Arbeit sollen die erkannten Textphrasen dann in Geokoordinaten überführt werden, um die erkannten Ortszugehörigkeiten von Vorschlägen auch kartenbasiert abbilden zu können.
Publikation
Padjman, Suzan (2021): Unterstützung der Auswertung von verkehrsbezogenen Bürger*innenbeteiligungsverfahren durch die automatisierte Erkennung von Verortungen. Projektarbeit am Institut für Informatik, Lehrstuhl für Datenbanken und Informationssysteme, der Heinrich-Heine-Universität Düsseldorf. (Download)
Verkehrswende konkret: Perspektiven der SÖF-Nachwuchsgruppen mit Schwerpunkt Mobilität

Gemeinsam mit CIMT starteten im Jahr 2019 zwei weitere BMBF-geförderten Nachwuchsgruppen in der sozial-ökologischen Forschung mit einem Fokus auf dem Verständnis und der Gestaltung der Verkehrswende: Experi, mit einem Fokus auf der Rolle von Reallaboren für die Mobilitätswende, und MoveMe mit einem besonderen Augenmerk auf den Besonderheiten für die Verkehrswende im suburbanen Raum.
In den letzten Jahren wurden zahlreiche theoretische und empirische Beiträge erarbeitet, und mittlerweile liegen in allen drei Nachwuchsgruppen zahlreiche Erkenntnisse vor. Im Rahmen eines gemeinsamen zweitägigen Workshops haben sich die drei Nachwuchsgruppen am 25. &. 26. Oktober in Hannover zu einem intensiven Austausch getroffen.
Ziel war die Vorstellung der jeweiligen Erkenntnisse, der Austausch über gemeinsame Herausforderungen, und die Identifikation möglicher Schnittstellen. Unter dem übergeordneten Anliegen der Gestaltung der Verkehrswende wurden dabei eine Reihe von Themen deutlich, zu denen in den Gruppen mit verschiedenen theoretischen Ansätzen und empirischen Methoden neue Perspektiven erarbeitet werden. Dazu gehören die Akzeptanz von Verkehrswendemaßnahmen, die Bedeutung von Partizipation und Konsultationsprozessen sowie die konkreten Optionen für eine Ausgestaltung zukünftiger Mobilität.
Der Workshop soll als Impuls dienen, in Zukunft verschiedene Formate der Zusammenarbeit auszuloten, z.B. in Form von gemeinsamen Veranstaltungen, Publikationen oder Projekten.
Metriken für eine stärker nutzendenzentrierte Evaluation der Klassifikationsgüte
In diesem Beitrag auf der 14th International Conference on Recent Advances in Natural Language Processing werden Metriken vorgestellt, um praxisrelevante Anforderungen der Einsetzbarkeit von KI-basierten Werkzeugen zu evaluieren.
Zusammenfassung
Eine Lösung für begrenzte Annotationsbudgets ist aktives Lernen (Active Learning / AL), ein gemeinschaftlicher Prozess von Mensch und Maschine zur strategischen Auswahl einer kleinen, aber informativen Menge von Beispielen. Während aktuelle Maßnahmen AL aus der Perspektive des maschinellen Lernens optimieren, argumentieren wir, dass für eine erfolgreiche Übertragung in die Praxis zusätzliche Kriterien auf die zweite Säule von AL, die menschlichen Annotator*innen und ihre Bedürfnisse, abzielen müssen. Beispielsweise wird der Nutzen von AL-Verfahren im Bereich der Textklassifikation durch gängige Gütemaße wie Accuracy oder F1 bewertet. Solche Maße greifen jedoch bei praxisnahen Datensätzen, die eine erhöhte Anzahl von unausgewogenen Klassen aufweisen, zu kurz, da hier weitere Kriterien wie das schnelle Finden aller Klassen (z.B. Themen) oder die Identifikation seltener Fälle eine Rolle spielen. Wir führen daher vier Maße ein, die die klassenbezogenen Anforderungen widerspiegeln, die Benutzer*innen an die Datenerfassung stellen.
In einem umfassenden Vergleich von Unsicherheits- (Uncertainty), Diversitäts- (Diversity) und hybriden Datenauswahlstrategien auf sechs verschiedenen Datensätzen stellen wir z.B. fest, dass eine starke F1-Leistung nicht unbedingt mit einer vollständigen Klassenabdeckung verbunden ist (d.h. es werden nicht alle Themen gefunden) und dass die verschiedenen Datenauswahlstrategien unterschiedliche Stärken und Schwächen bezüglich der klassenbezogenen Anforderungen aufzeigen. Unsere empirischen Ergebnisse unterstreichen, dass eine ganzheitliche Betrachtung bei der Bewertung von AL-Ansätzen unerlässlich ist, um ihre Nützlichkeit in der Praxis sicherzustellen. Zu diesem Zweck müssen Standardmaße für die Bewertung von maschinellen Textklassifikationsverfahren durch solche ergänzt werden, die die Bedürfnisse der Nutzer besser widerspiegeln.
Wesentliche Ergebnisse
- In dieser Publikation werden vier neue klassenbezogene Gütemaße für AL-Ansätze vorgeschlagen, die berücksichtigen, wie gut und schnell seltene oder alle Klassen erkannt werden. Diese Kriterien werden von Standardmaßen (z.B. F1) nicht im Detail berücksichtigt.
- Die neuen Maße ermöglichen praxisrelevante Einsichten in die Performanz insbesondere auf Datensätzen mit unterschiedlichen oft vorkommenden Klassen sowie einer großen Spanne an verschiedenen Klassen – Eigenschaften, die in der Praxis (z.B. bei der Themenerkennung in Beteiligungsverfahren) weit verbreitet sind.
- Es zeigt sich, dass die Wahl einer geeigneten AL-Strategie nicht nur aufgrund von Standardmaßen getroffen werden sollte. Die besten Ansätze nach dem F1-Maß können z.B. nicht sicherstellen, dass auch alle Klassen gefunden werden, obgleich dies eine essenzielle Anforderung in der automatisierten Auswertung von Beteiligungsbeiträgen ist: kein Thema sollte vernachlässigt werden, keine Stimme untergehen. Die von uns entwickelten Maße können die Auswahl zusätzlich informieren und so praxisorientierte Lösungen liefern.
Publikation
Romberg, J. (2023). Mind the User! Measures to More Accurately Evaluate the Practical Value of Active Learning Strategies. Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing, 996–1006. https://aclanthology.org/2023.ranlp-1.107/
Übersicht über Ansätze computerbasierter Textanalyse zur Unterstützung der Auswertung von Beiträgen aus Öffentlichkeitsbeteiligungen
In diesem Artikel in der Zeitschrift Digital Government: Research and Practice geben Julia Romberg und Tobias Escher einen Überblick über automatisierte Techniken die bereits zur Unterstützung der Auswertung von Beiträgen in Beteiligungsprozessen verwendet wurden. Auf Basis einer systematischen Literaturstudie bewerten sie die Leistungsfähigkeit der bisher eingesetzten Verfahren und zeigen weiteren Forschungsbedarf auf.
Zusammenfassung
Öffentliche Institutionen, die Bürger*innen im Rahmen politischer Entscheidungsprozesse konsultieren, stehen vor der Herausforderung, die Beiträge der Bürger*innen auszuwerten. Unter demokratischen Aspekten ist diese Auswertung von wesentlicher Bedeutung, benötigt gleichzeitig aber umfangreiche personelle Ressourcen. Eine bislang noch zu wenig erforschte Lösung für dieses Problem bietet die Nutzung von künstlicher Intelligenz, wie beispielsweise computer-unterstützter Textanalyse. Wir identifizieren drei generische Aufgaben im Auswertungsprozess, die von der automatisierten Verarbeitung natürlicher Sprache (NLP) profitieren könnten. Auf Basis einer systematischen Literaturrecherche in zwei Datenbanken zu Computerlinguistik und Digital Government geben wir einen detaillierten Überblick über die existierenden Ansätze und deren Leistungsfähigkeit. Auch wenn teilweise vielversprechende Ansätze existieren, beispielsweise um Beiträge thematisch zu gruppieren oder zur Erkennung von Argumenten und Meinungen, so zeigen wir, dass noch bedeutende Herausforderungen bestehen, bevor diese in der Praxis zuverlässig zur Unterstützung eingesetzt werden können. Zu diesen Herausforderungen zählt die Qualität der Ergebnisse, die Anwendbarkeit auf nicht-englischsprachige Korpora und die Bereitstellung von Software, die diese Algorithmen auch Praktikter*innen zugänglich macht. Wir diskutieren verschiedene Ansätze zur weiteren Forschung, die zu solchen praxistauglichen Anwendungen führen könnten. Die vielversprechendsten Ansätze integrieren die Expertise menschlicher Analyst*innen, zum Beispiel durch Ansätze des Active Learning oder interaktiver Topic Models.
Ergebnisse
- Es gibt eine Reihe von Aufgaben im Auswertungsprozess, die durch die automatisierte Verarbeitung natürlicher Sprache (NLP) unterstützt werden könnten. Dazu gehören i) die Erkennung von Duplikaten, ii) die thematische Gruppierung von Beiträgen, und iii) die detaillierte Analyse einzelner Beiträge. Der Großteil der Literatur in dieser Literaturstudie konzentriert sich auf die automatisierte Erkennung und Analyse von Argumenten, einen Aspekt der detaillierten Analyse einzelner Beiträge.
- Wir stellen eine umfangreiche Zusammenfassung der genutzten Datensätze und der verwendeten Algorithmen vor, und bewerten deren Leistungsfähigkeit. Trotz der ermutigenden Ergebnisse wurde die deutlichen Entwicklungssprünge, in den letzten Jahren im NLP-Bereich erfolgt sind, bislang kaum für diesen Anwendungsfall genutzt.
- Eine besondere auffällige Lücke besteht in der mangelnden Verfügbarkeit von Anwendungen, die Praktiker*innen die einfache Nutzung von NLP-basierten Verfahren für die Auswertung ihrer Daten erlauben würden.
- Der Aufwand zur Erstellung von annotierten Daten, die zum Training von Modellen des maschinellen Lernens notwendig sind, kann dazu führen, dass sich die erhofften Effizienzvorteile einer automatisierten Auswertung nicht einstellen.
- Wir empfehlen verschiedene vielversprechendsten Ansätze zur weiteren Forschung. Viele davon integrieren die Expertise menschlicher Analyst*innen, zum Beispiel durch Ansätze des Active Learning oder interaktiver Topic Models.
Publikation
Romberg, Julia; Escher, Tobias (2023). Making Sense of Citizens’ Input through Artificial Intelligence: A Review of Methods for Computational Text Analysis to Support the Evaluation of Contributions in Public Participation. In: Digital Government: Research and Practice 5(1): 1-30. DOI: 10.1145/3603254.